Yuan 3.0, another Multimodal Model that can significantly change document AI



We previously talked about DeepSeek V2 OCR and why it is meaning in Document AI.
But we feel Yuan 3.0 could be another major upgrade.
Last week, YuanLab.ai released Yuan3.0 Flash — a 40B parameter open-source multimodal model built on a Mixture-of-Experts (MoE) architecture that activates only 3.7B parameters per inference. And if you care about Document AI in enterprise settings, this model deserves serious attention.
Quick Recap: What DeepSeek-OCR 2 Brought to the Table
DeepSeek-OCR 2 introduced a genuinely new idea: instead of processing image patches in rigid left-to-right, top-to-bottom order, it uses a language model as an encoder that dynamically reorders visual tokens based on the semantic structure of the document. Headers get read before body text. Table cells follow logical row/column order. Multi-column layouts get parsed correctly — not because someone hardcoded rules, but because the model learned the causal flow of information.
That was an architectural breakthrough in how machines read documents. But it was focused primarily on the encoder — on fixing how visual information gets ordered before the language model reasons over it.
Yuan 3.0 Flash takes a different approach entirely. It doesn't just improve how images get read — it rethinks the entire pipeline from how the model ingests documents, tables, and images natively as first-class inputs to how it reasons over them efficiently in enterprise workflows.
What Makes Yuan 3.0 Flash Different
Yuan 3.0 Flash was built from the ground up for enterprise document workflows. While most multimodal models treat documents and tables as an afterthought — something you can kind of do if you squint — Yuan 3.0 was explicitly designed and trained to ingest tables, documents, and mixed-format content as native multimodal inputs.
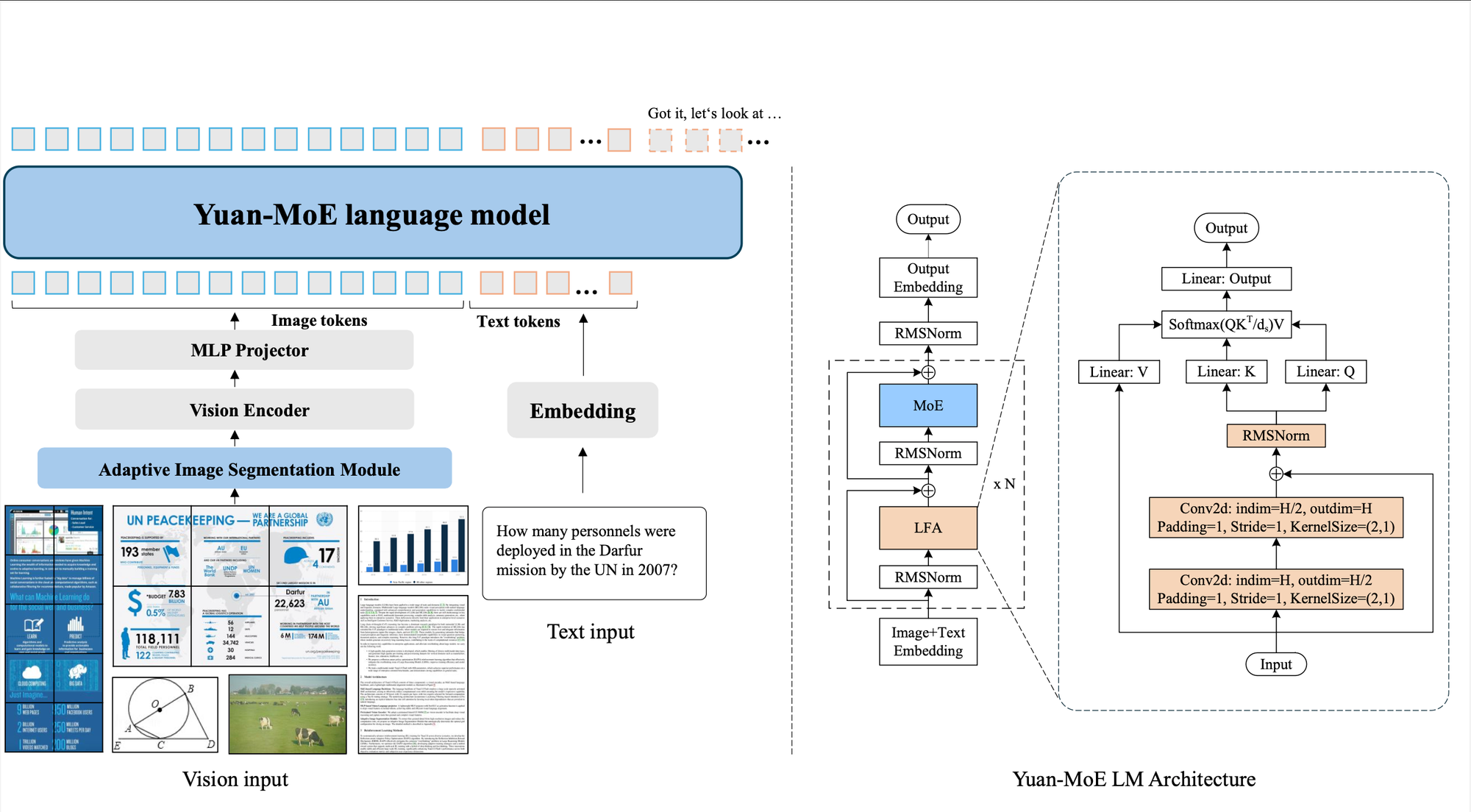
The architecture has three core components: a pretrained InternViT-300M vision encoder for processing images, a lightweight MLP projector with SwiGLU activations for aligning visual features with text, and a MoE-based language backbone with 40 layers, 32 experts per layer, and a Top-K routing strategy that selects only 2 experts per forward pass. The backbone also uses Localizing Filtering-based Attention (LFA), which adds an explicit inductive bias toward local token dependencies — particularly important for structured content like tables and form fields where nearby tokens carry strong relational meaning.
But the architecture alone isn't what makes this interesting. It's the combination of native multimodal ingestion, enterprise-focused training data, and a novel approach to efficient reasoning that makes Yuan 3.0 a potential game-changer for Document AI.
Native Document and Table Understanding — Not Bolted On
Here's the fundamental difference that matters for Document AI practitioners: Yuan 3.0 Flash natively supports text, image, table, and document inputs as distinct modalities. This isn't a vision-language model that happens to handle documents. The training pipeline was specifically designed with enterprise document scenarios in mind.
The fine-tuning dataset tells the story: 45,000 human-expert-annotated dialogues (20,000 of which are multimodal, including code snippets, diagrams, and API screenshots), plus 305,000 synthetic samples spanning domains like finance, law, manufacturing, healthcare, and education. They also built a high-quality data generation system that filters multimodal data types across vertical enterprise domains — not general internet crawl data, but data that reflects how businesses actually use documents.
The model also includes an Adaptive Image Segmentation Module that automatically determines the optimal grid configuration for slicing high-resolution images. For document processing, this means the model can handle everything from a small receipt to a full-page dense financial report without manual preprocessing, dynamically adjusting how it partitions and processes the visual input.
The Numbers That Matter for Document AI
Let's talk benchmarks, because this is where Yuan 3.0 Flash gets genuinely impressive.
Multimodal RAG (Docmatix benchmark): Yuan3.0 Flash scores 65.07% average accuracy — beating Claude 3.5 Sonnet (42.55%), GPT-4o (56.79%), GPT-o3 (45.57%), and even GPT-5.1 (48.52%). This benchmark evaluates a model's ability to retrieve, correlate, and accurately answer questions across text, tables, and images within multi-page complex documents. For enterprise document processing, this is arguably the most relevant benchmark that exists.
Complex Table Understanding (MMTab benchmark): Yuan3.0 Flash achieves a leading 58.29% average accuracy across 15 evaluation tasks — surpassing GPT-5.1 (55.15%) and dramatically outperforming GPT-4V (29.90%). On TABMWP (table-based math word problems), it scores an extraordinary 95.09%. On TabFact (fact checking against tables), 87.32%. These aren't marginal improvements. If your business relies on extracting structured data from complex tables — financial reports, manufacturing specs, regulatory filings — this is a step change.
Text-based RAG (ChatRAG benchmark): Across 10 tasks in the industry-standard ChatRAG benchmark, Yuan3.0 Flash leads with 64.47% average accuracy — significantly ahead of DeepSeek-V3 (50.47%), GPT-4o (50.54%), and GPT-5.1 (46.10%). It achieves leading performance on 9 out of 10 tasks. For anyone building RAG-powered document workflows — which is most enterprise AI applications today — this is a standout result.
Summarization (SummEval): Yuan3.0 Flash scores 59.31% average across lexical overlap, semantic similarity, and factual consistency — beating DeepSeek-V3 (59.28%), and significantly outperforming Gemini 2.0 Flash (45.35%), Claude 3.5 Sonnet (45.43%), and GPT-5.1 (49.44%). In document automation, summarization quality directly impacts how useful extracted information is downstream.
The Efficiency Breakthrough: RAPO and Why It Matters
Performance is one thing. But for enterprise Document AI, cost and speed matter just as much as accuracy. This is where Yuan 3.0 introduces something genuinely novel.
Large reasoning models have an "overthinking" problem. After arriving at the correct answer, they keep going — self-checking, verifying, reflecting — consuming tokens and compute for no benefit. The YuanLab team's analysis of DeepSeek-R1 found that up to 71.6% of token consumption occurs in this post-answer reflection phase. That's an enormous amount of wasted inference.
Yuan 3.0 tackles this with RAPO (Reflection-aware Adaptive Policy Optimization), a reinforcement learning algorithm that identifies the point where the model first arrives at the correct answer and then suppresses redundant reasoning afterward. The results are dramatic: compared to standard RL training, RAPO improves accuracy by up to 52% while simultaneously reducing output tokens by up to 75%.
For document processing at scale, this efficiency gain is transformative. If you're processing millions of invoices, contracts, or financial statements, using 75% fewer tokens per document doesn't just mean faster processing — it means dramatically lower costs. The MoE architecture compounds this: only 3.7B of the 40B parameters activate per inference, so you get large-model quality with small-model compute costs.
DeepSeek-OCR 2 vs. Yuan 3.0: Different Approaches, Complementary Strengths
It's worth being precise about what each model brings to Document AI, because they solve different parts of the problem.
DeepSeek-OCR 2 is fundamentally an encoder innovation. It solved the reading order problem — how to get visual tokens into the right sequence before the language model reasons over them. It uses Visual Causal Flow to create a semantic ordering of image patches, and it does this with remarkable token efficiency (256 to 1,120 visual tokens vs. 6,000+ for competing models). For pure document OCR — extracting text from complex layouts — it's a breakthrough.
Yuan 3.0 Flash is a full-stack enterprise solution. It doesn't just read documents better — it reasons over them, retrieves from them, understands tables natively, generates summaries, and does all of this while consuming a fraction of the tokens that other models need. It supports 128K context length with 100% accuracy on Needle-in-a-Haystack tests, meaning it can process and reason over long multi-page documents without losing information.
Think of it this way: DeepSeek-OCR 2 gives you a better set of eyes. Yuan 3.0 gives you a better brain — one that was trained specifically to think about documents.
Why This Matters for Enterprise Document Workflows
The practical implications for businesses that process documents at scale are significant.
First, the RAG performance gap is enormous. Most enterprise AI applications today are RAG-based — you have a corpus of documents, and you need a model that can retrieve relevant information and answer questions accurately. Yuan 3.0 outperforms every major model on both text-based and multimodal RAG benchmarks by wide margins. A 14-point lead over GPT-4o on ChatRAG isn't incremental improvement — it's a different tier of capability.
Second, table understanding has always been the weak link in Document AI. Financial statements, insurance forms, medical records, compliance reports — they're all full of tables. Most models struggle with anything beyond simple grids. Yuan 3.0's native table support and leading MMTab scores suggest it can handle the complex, nested, multi-format tables that real enterprise documents contain.
Third, the cost equation changes. With MoE activating only 3.7B of 40B parameters, plus RAPO reducing token consumption by up to 75%, the cost-per-document for enterprise processing could drop dramatically. This is the difference between an AI document pipeline that works in a demo and one that's economically viable at scale.
Fourth, it's fully open source with a commercial license. The model weights, code, and fine-tuning scripts are all available on GitHub and HuggingFace — including a 4-bit quantized version for deployment on more modest hardware. For enterprises that need to run models on-premises for compliance or security reasons, this is a major advantage over API-only models.
The Caveats
Let's be honest about the limitations. On general multimodal benchmarks like DocVQA and MathVista, Yuan 3.0 Flash still trails models like Qwen3-VL-32B and Qwen2.5-VL-72B. It scores 90.1% on DocVQA compared to Qwen3-VL's 96.9%. For pure visual reasoning tasks, it's competitive but not leading.
On general reasoning benchmarks like AIME 2024 and GPQA-Diamond, the gap with models like DeepSeek-R1 is significant. Yuan 3.0 wasn't built to be the best general reasoning model — it was built to be the best enterprise document model. That's a deliberate trade-off, and for Document AI use cases, it's the right one.
The model is also new and hasn't been battle-tested in production environments yet. Benchmark results don't always translate to real-world performance, especially with the messy, inconsistent documents that enterprises actually deal with. We'll need to see how it performs on real document pipelines before drawing definitive conclusions.
And Then There's Yuan3.0 Ultra
Just as we were writing this post, YuanLab released something even bigger: Yuan3.0 Ultra, a 1.01 trillion parameter flagship model with 68.8B activated parameters, released in early March 2026. If Flash is the efficient workhorse, Ultra is the heavyweight.
Ultra pushes the Document AI benchmarks even further: 67.4% on Docmatix (up from Flash's 65.07%), 68.2% on ChatRAG (up from 64.47%), and 62.3% on MMTab (up from 58.29%). It also adds new capabilities like Text-to-SQL generation and stronger tool invocation for agent workflows. On SummEval, it reaches 62.8%, extending the lead over every competing model.
The engineering is interesting too. Ultra was originally pre-trained at 1,515B parameters, then pruned down to 1,010B during training using a new technique called Layer-Adaptive Expert Pruning (LAEP). LAEP identifies underutilized experts layer by layer during the stable phase of training and removes them, improving pre-training efficiency by 49% and reducing the parameter count by a third — without sacrificing performance. This is a meaningful contribution to making trillion-parameter MoE models practical to train.
For enterprises, the choice between Flash and Ultra comes down to deployment constraints. Flash (40B total, 3.7B activated) is the one you can run on-premises on reasonable hardware, especially with the 4-bit quantized version. Ultra (1.01T total, 68.8B activated) delivers the best absolute performance but requires significantly more infrastructure. Both are fully open source with commercial licenses, which means you can evaluate both and choose based on your specific accuracy-vs-cost requirements.
The Bottom Line
When we wrote about DeepSeek-OCR 2, we said it represented a new architectural paradigm for how machines read documents. Yuan 3.0 Flash represents something adjacent but equally important: a model purpose-built for the entire enterprise document workflow, not just the reading step.
The fact that a 40B MoE model activating only 3.7B parameters can beat GPT-5.1 on enterprise document benchmarks while using a fraction of the tokens is a signal that the industry is moving toward specialized, efficient models rather than ever-larger general-purpose ones. For Document AI specifically, that's very good news. The model weights and code are open source on GitHub. The paper is on arXiv. If you're building document automation pipelines, this one is worth evaluating.
Softmax Data builds AI agents and document automation for businesses. If you're exploring what AI can do for your document workflows, let's talk.