What is Google's KV Cache and will it resolve the Chip shortage?



If you've been following the AI hardware race, you've probably heard that GPUs are the new gold. Companies are spending billions on chips just to keep large language models running. But what if a big chunk of that cost comes not from the actual "thinking" a model does, but from it constantly re-reading its own notes? That's essentially the problem that KV Cache — short for Key-Value Cache — is designed to solve.
Let's break it down.
How LLMs Generate Text (The Slow Way)
To understand KV Cache, you first need to know how a large language model like GPT or Gemini generates text. These models produce words one at a time. When you ask it "What is the capital of France?", it doesn't instantly blurt out "Paris." Instead, it goes through a process more like this:
It reads your entire prompt, does a massive amount of math, and produces the first word: "The." Then, to produce the next word, it reads your entire prompt again plus the word "The," does all that math again, and outputs "capital." Then it reads everything again — your prompt, "The," "capital" — and outputs "of." And so on.
Imagine you're writing an essay, but every time you want to write the next sentence, you re-read the entire essay from the very beginning. You'd never forget anything, sure — but you'd be absurdly slow. That's basically what an LLM does without KV Cache.
So What Exactly Is KV Cache?
The "Key" and "Value" in KV Cache come from the attention mechanism — the core engine inside a transformer model. Without diving too deep into the math, here's the intuition: when a model processes a sentence, each word creates two important things — a Key (think of it as a label that says "here's what I'm about") and a Value (the actual information that word carries). A third vector, the Query, is used by the new word being generated to ask "which previous words should I pay attention to?"
Without caching, the model recomputes all of those Keys and Values for every previous word, every single time it generates a new token. KV Cache simply says: we already computed the Keys and Values for the earlier words — let's save them in memory and reuse them. Only the new word needs fresh computation.
Going back to the essay analogy: instead of re-reading your entire essay every time, you keep detailed sticky notes of the key ideas from each paragraph. When you write the next sentence, you glance at your sticky notes instead of re-reading everything. Much faster.
The Catch: KV Cache Is a Memory Hog
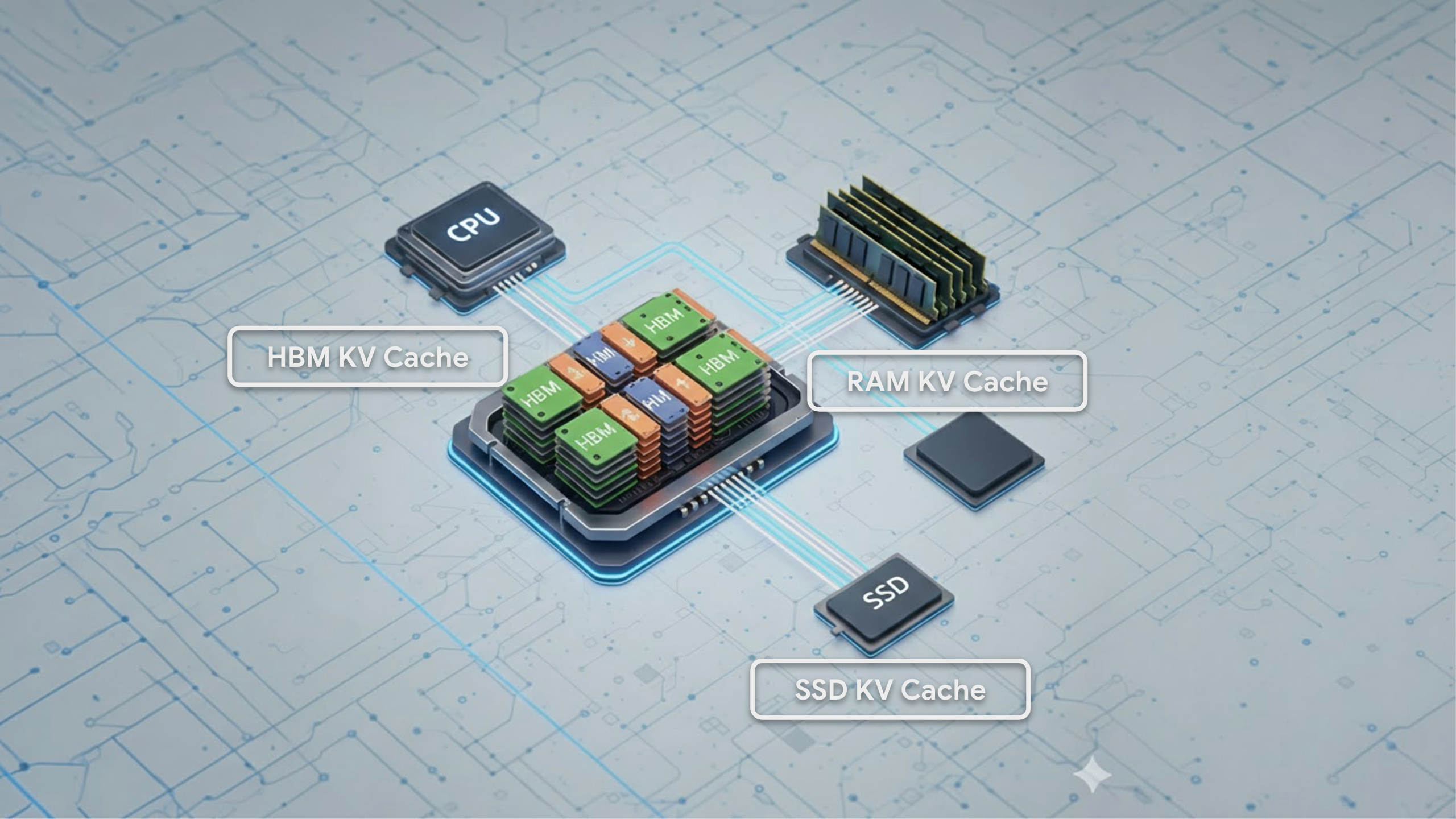
Here's where it gets interesting — and where the connection to chip shortages comes in. KV Cache trades compute for memory. Instead of re-doing math, you store results in GPU memory (specifically, the High Bandwidth Memory, or HBM, on chips like NVIDIA's H100). The problem is that this memory is extremely scarce and expensive.
For a large model like Llama 3 70B handling a long conversation, the KV Cache alone can consume tens of gigabytes of HBM per user session. When you're serving millions of users concurrently, this adds up astronomically. In many production deployments, the KV Cache — not the model weights — becomes the dominant consumer of GPU memory.
Think of it like this: you've upgraded from re-reading your entire essay to using sticky notes, but now your desk is completely buried in sticky notes and you need a bigger desk. That bigger desk is more HBM, which means more GPUs, which means more money and more chips.
What Google (and Others) Are Doing About It
This is where recent innovations come in, including the two papers linked above. The industry is attacking this problem from multiple angles.
The first approach is quantization — compressing the KV Cache. Google's TurboQuant and similar techniques take the cached Key and Value tensors and represent them using fewer bits. Instead of storing each value as a 16-bit floating point number, you might squeeze it down to 4 bits or even 2 bits. This is like replacing your detailed sticky notes with abbreviated shorthand. You lose a tiny bit of precision, but your desk suddenly has room again. Google's research suggests you can compress KV Cache by 4-8x with negligible impact on output quality for many tasks.
The second approach is tiered storage. Google Cloud's blog post describes moving parts of the KV Cache off the GPU's precious HBM and onto cheaper, more abundant memory — like the CPU's regular RAM or even local SSDs. Not all cached data is accessed equally often, so the "hot" data stays on the GPU while "cold" data gets offloaded. This is similar to how your computer already manages memory: frequently used data stays in fast RAM, while less-used data gets swapped to disk.
A third approach, used by architectures like Multi-Query Attention (MQA) and Grouped-Query Attention (GQA), reduces the size of the KV Cache at the model architecture level. Instead of every attention "head" maintaining its own separate set of Keys and Values, multiple heads share them. This can reduce KV Cache size by 4-8x right at the design stage.
Can KV Cache Optimization Help With the Chip Shortage?
Now for the big question. The short answer: it helps, but it won't single-handedly solve the problem.
Here's why it matters. The global AI chip shortage is fundamentally a supply-and-demand mismatch. Demand for AI compute is growing exponentially — driven by larger models, longer contexts, and more users — while fabricating advanced chips takes years of lead time and billions in capital investment. KV Cache optimization attacks the demand side of this equation. If you can serve the same model to the same number of users with half the GPU memory, you effectively double your fleet's capacity without buying a single new chip.
Consider the math. If KV Cache quantization achieves a 4x compression ratio, and KV Cache was consuming 60% of your GPU memory during inference, you've just freed up roughly 45% of your total HBM. That freed memory means you can handle more concurrent users per GPU, or serve longer conversations, or run a larger model on the same hardware. At datacenter scale, this translates directly into fewer GPUs purchased, fewer racks deployed, and less power consumed.
On the energy front, the impact is equally significant. GPU memory access is one of the most energy-hungry operations in AI inference. Reducing KV Cache size means fewer memory reads and writes, which directly lowers the energy per token generated. Tiered caching adds another dimension: offloading data to CPU RAM or SSDs uses a fraction of the energy that HBM access requires for data that isn't needed at high speed. When you multiply these savings across the millions of inference requests that a company like Google handles every minute, the aggregate energy reduction is substantial.
But Here's the Reality Check
There's a well-known phenomenon in computing called the Jevons Paradox: when you make a resource more efficient to use, people often end up using more of it, not less. We've seen this play out repeatedly in tech. Faster internet didn't reduce bandwidth demand — it exploded it. More fuel-efficient cars didn't reduce total gasoline consumption for decades.
The same dynamic is almost certainly at play with AI inference. Every efficiency gain that KV Cache optimization delivers will likely be absorbed by expanding use cases: longer context windows (we've already gone from 4K tokens to 1M+), more agents running in parallel, always-on AI assistants, and entirely new applications that weren't feasible when inference was more expensive. So while KV Cache optimizations will make each individual inference call cheaper and less resource-intensive, the total number of inference calls is likely to grow even faster.
KV Cache optimization also doesn't address the training side of AI compute, which is where much of the current chip demand comes from. Training a frontier model still requires thousands of GPUs running for months, and KV Cache is primarily an inference-time technique.
Finally, the chip shortage isn't just about total memory demand. It's about manufacturing capacity at TSMC and Samsung, about the geopolitics of semiconductor supply chains, about the multi-year timelines for building new fabs. Software optimizations, however clever, can't build a fabrication plant.
The Bottom Line
KV Cache is one of the most important yet under-discussed components of modern AI infrastructure. It's the reason your chatbot responds in seconds rather than minutes. And the current wave of KV Cache optimizations — quantization, tiered storage, architectural changes — represents a genuine and meaningful step toward making AI inference more efficient.
Will it resolve the chip shortage? No. But it's one of the most impactful levers the industry has right now for stretching existing hardware further. Think of it as buying time: every 2x improvement in KV Cache efficiency is essentially one fewer generation of GPU upgrades that a company needs to deploy immediately. In an industry where a single GPU costs $30,000+ and a training cluster can run into the hundreds of millions, that's not nothing.
The chip shortage will ultimately be resolved by a combination of new fab capacity, architectural innovation (at both the chip and model level), and probably a maturation of demand growth. KV Cache optimization is a critical piece of the puzzle — just not the whole picture.